
Web Crawlers and Web Crawling
07 Jul 2017
Ever wondered how a search engine comes up with the exact results when you type something in its query box? After all, there are trillions of results matching your search query. A fascinating process is at work behind it. It is the Web Crawler that is responsible for accomplishing the task. So what is a web crawler, what it does and how it does, I will try to answer all these.
What is a Web Crawler
Web Crawler or simply a Crawler is a program that acts as an automated script which browses through the internet in a systematic way.
Web Crawlers are also known as Spiders, Robot, SearchBot or simply Bot. Web crawlers are one of the most common used systems now-a-days. The most popular example is that Google is using crawlers to collect information from all websites.
A Search Engine Spider is a program that most search engines use to find what’s new on the Internet. The crawler looks at the keywords in the pages, the kind of content each page has and the links, before returning the information to the search engine. This process is known as Web crawling.
Besides search engine, news websites need crawlers to aggregate data sources. It seems that whenever you want to aggregate a large amount of information, you may consider using crawlers.
Why is Web Crawling Important
Let me make you understand with an example to show why web crawling is important.
Data lies in the heart of any business, even more if its tech related. With all the open standards of today like RSS feeds or APIs sharing data across systems have become relatively easier.
For example, if you want to read today’s financial news directly from your email inbox, you could simply subscribe to the provider’s (like Google News or BBC) RSS feed. Similarly, your system or application could also use a provider’s API to get upto date information. But what about data that is unstructured or does not have RSS feeds for you to consume? How will you go about fetching them?
Let’s consider another simple example. Suppose you have a shopping site and have 1000 products. You want to make sure your prices are competitive. In order to do that, you will need to monitor your competitors’ sites and their prices for the same products. If there are a lot of products and lot of competitors it is going to be very difficult to do this without some automated process.
This is where Web Crawling comes into picture.
Web Crawling technology was made popular by Google for its use in their search. They were the first to see the importance of immense amount of data on the web which was then not crawled and indexed. They capitalized on that – sent out thousands of crawlers to the web and indexed everything they could possibly find!
To sum up let’s get few points summarized as to why web crawling is important:
-
Gather data for business intelligence.
-
Market research about the product or service you are offering.
-
Monitor competitor’s product or solution 24/7.
-
Gather user behavior data to make your product perform better.
How does a Web Crawler work
In short as explained by Google on how Google Search works, for web crawling procedure there are mainly three steps:
- First, the search bot starts by crawling the pages of your site(Crawling).
- Then it continues indexing the words and content of the site(Indexing), and
- finally it visit the links (web page addresses or URLs) that are found in your site.
To control the way a spider looks to your website is by using a robots.txt file. The first thing a spider is supposed to do when it visits your website is look for a file called robots.txt. This file contains instructions for the spider on which parts of the website to index, and which parts to ignore.
Another piece of information I would share is the following answer in Quora, when asked
What are some ideas of how a startup can use web crawler scripts to drive growth?
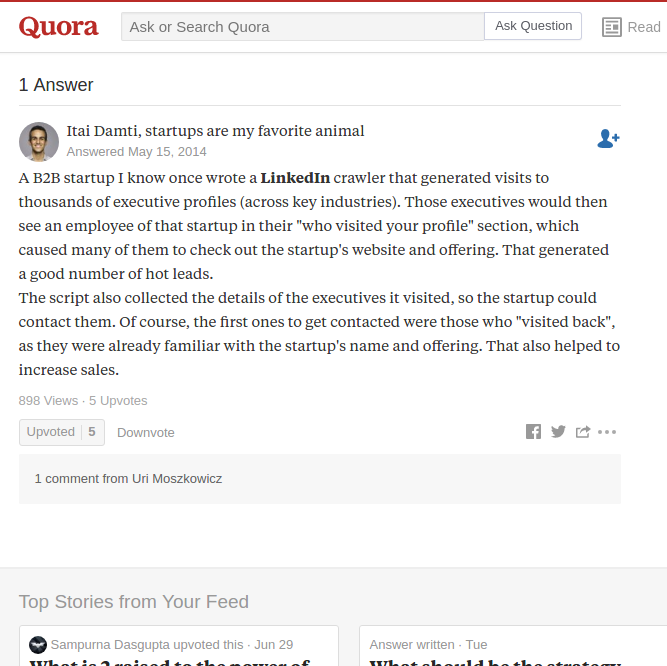
This was just an idea about web crawlers and web crawling. Hope, this might help you to get started with crawlers. Till then All the Best 👍 and Happy Coding 😃